Humanoid robot technology is advancing rapidly, with manufacturers introducing diverse heterogeneous visual perception modules tailored to specific scenarios. Among various perception paradigms, occupancy-based representation has become widely recognized as particularly suitable for humanoid robots, as it provides both rich semantic and 3D geometric information essential for comprehensive environmental understanding. In this work, we present Humanoid Occupancy, a generalized multimodal occupancy perception system that integrates hardware and software components, data acquisition devices, and a dedicated annotation pipeline. Our framework employs advanced multi-modal fusion techniques to generate grid-based occupancy outputs encoding both occupancy status and semantic labels, thereby enabling holistic environmental understanding for downstream tasks such as task planning and navigation. To address the unique challenges of humanoid robots, we overcome issues such as kinematic interference and occlusion, and establish an effective sensor layout strategy. Furthermore, we have developed the first panoramic occupancy dataset specifically for humanoid robots, offering a valuable benchmark and resource for future research and development in this domain. The network architecture incorporates multi-modal feature fusion and temporal information integration to ensure robust perception. Overall, Humanoid Occupancy delivers effective environmental perception for humanoid robots and establishes a technical foundation for standardizing universal visual modules, paving the way for the widespread deployment of humanoid robots in complex real-world scenarios.
Humanoid Occupancy
Enabling A Generalized Multimodal Occupancy Perception System on Humanoid Robots
We present a multimodal occupancy perception system tailored for humanoid robots, encompassing the complete hardware and software stack, including sensor configurations, data acquisition, data annotation, and perception networks.
Abstract
Sensor Layout and Data Acquisition

Side View

Isometric View

Data Acquisition
Sensor Layout. Our sensor consists of 6 cameras and a LiDAR. The 6 cameras use standard RGB sensors, arranged in a way that one is arranged in the front and back, and two are arranged on each side. The horizontal FOV of the camera is 118 degrees and the vertical FOV is 92 degrees. The LiDAR uses a 40-line 360-degree omnidirectional LiDAR with a vertical FOV of 59 degrees.
Data Acquisition. We use a wearable device with the same sensor configuration as humanoid robots to collect data. Human data collectors around 160 cm tall wear it directly on their heads to ensure the sensor height matches that of the final installation on the robot. A neck stabilizer is added to prevent head shaking during collection, and the collectors' walking speed is limited to no more than 1.2 meters per second with turning angular speed not exceeding 0.4 radians per second.
Annotation Pipeline
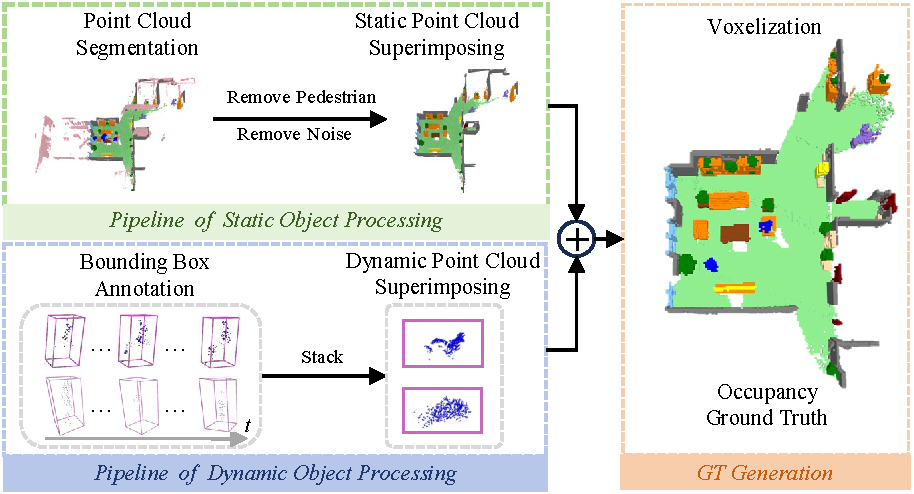
The Occupancy Generation Pipeline
The annotation process is divided into three parts. First, static and dynamic objects are processed separately. Dynamic objects are directly annotated with bounding boxes. For static object processing, we first remove the point clouds of dynamic objects, then remaining static points are superimposed onto multi-frame point clouds, and point-level semantic annotation is performed. Finally, the dynamic and static scenes along with their annotations are merged: the superimposed static background points are aligned to the ego coordinate system of frame-by-frame point clouds, while the dynamic foreground points are spliced into the point cloud based on the poses of dynamic objects in each frame. This merged point cloud is directly voxelized to obtain the ground truth without Poisson reconstruction.
Multi-Modal Fusion Network
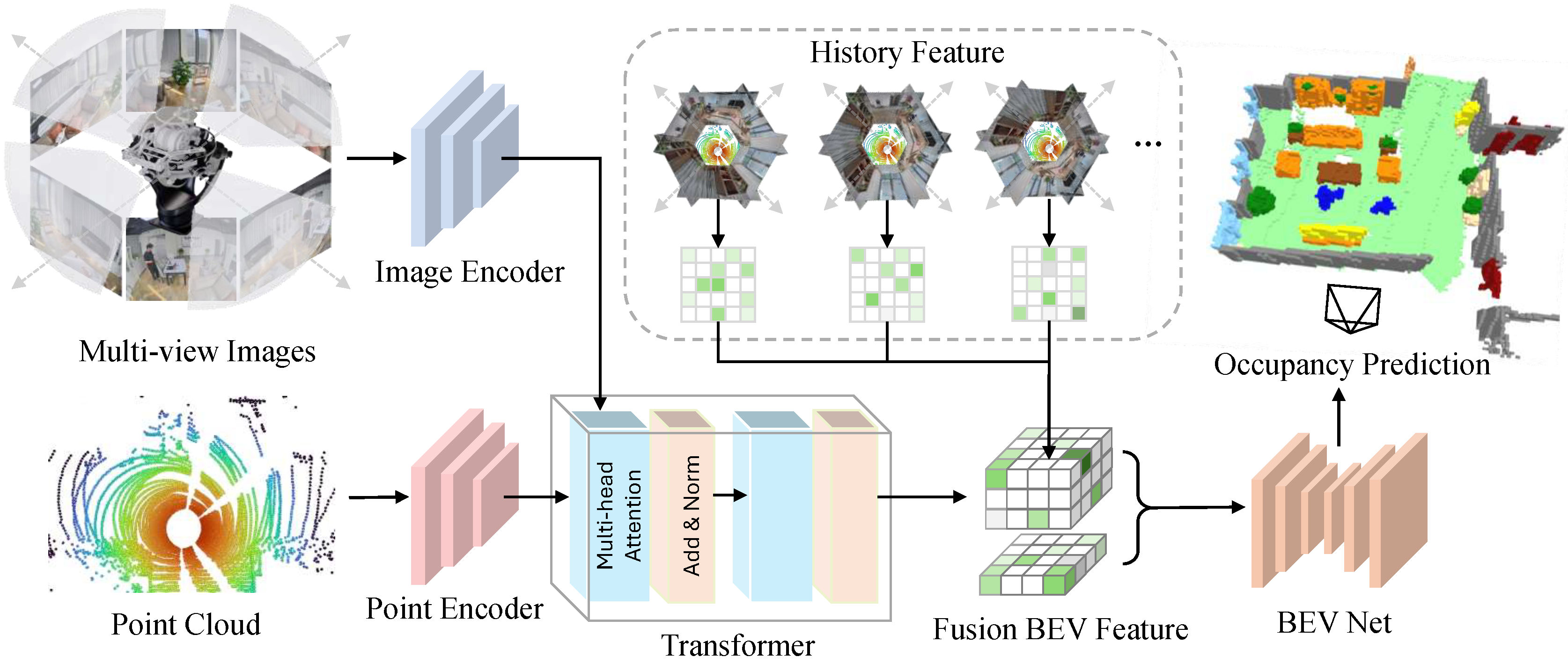
The Model Architecture
Our occupancy perception model accepts multimodal inputs, including a LiDAR point cloud and 6 pinhole camera images. We use the Bird's Eye View (BEV) paradigm that has been widely validated and adopted in autonomous driving for feature extraction and feature fusion. Since the robotic sensors undergo pitch and roll motions during movement, it is essential to transform the sensor data into a gravity-aligned egocentric reference frame to comply with the BEV assumption. Specifically, we extract LiDAR and camera features through two modality-specific feature extraction branches, and then perform multi-modal feature fusion through Transformer Decoder. The final occupancy result is predicted on the fused BEV features.
Experiments and Results
Experiments are conducted on our collected data, including 180 training clips and 20 validation clips. Metrics used for evaluation are mIoU and rayIoU. The perception range is set as [-10m, 10m] for the X and Y axes, and [-1.5m, 0.9m] for the Z-axis in the ego coordinate system.
Benchmark
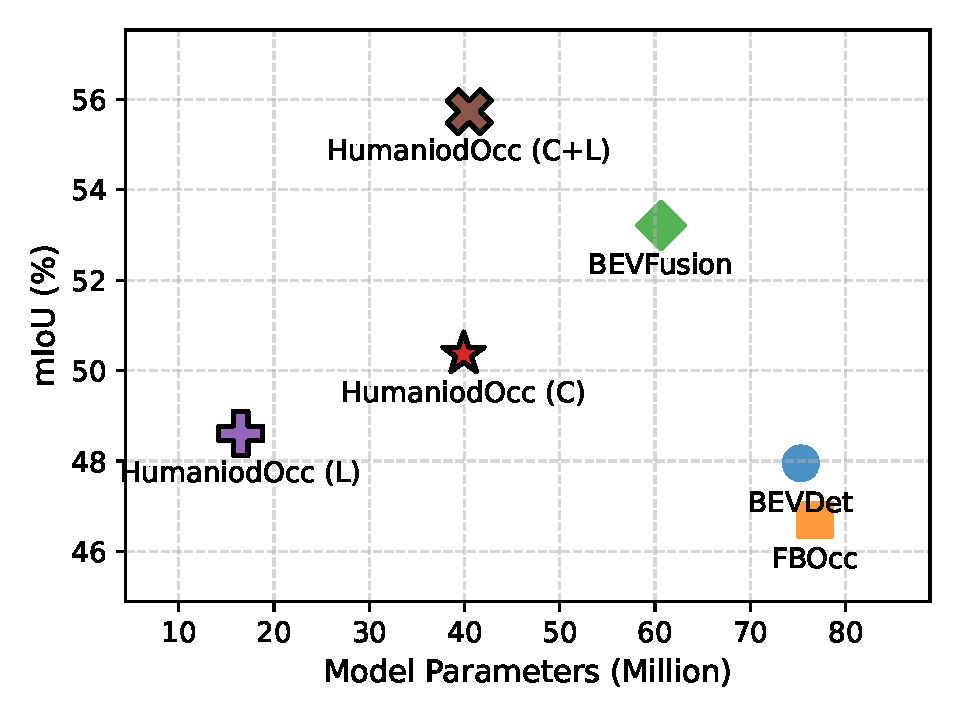
mIoU Performance
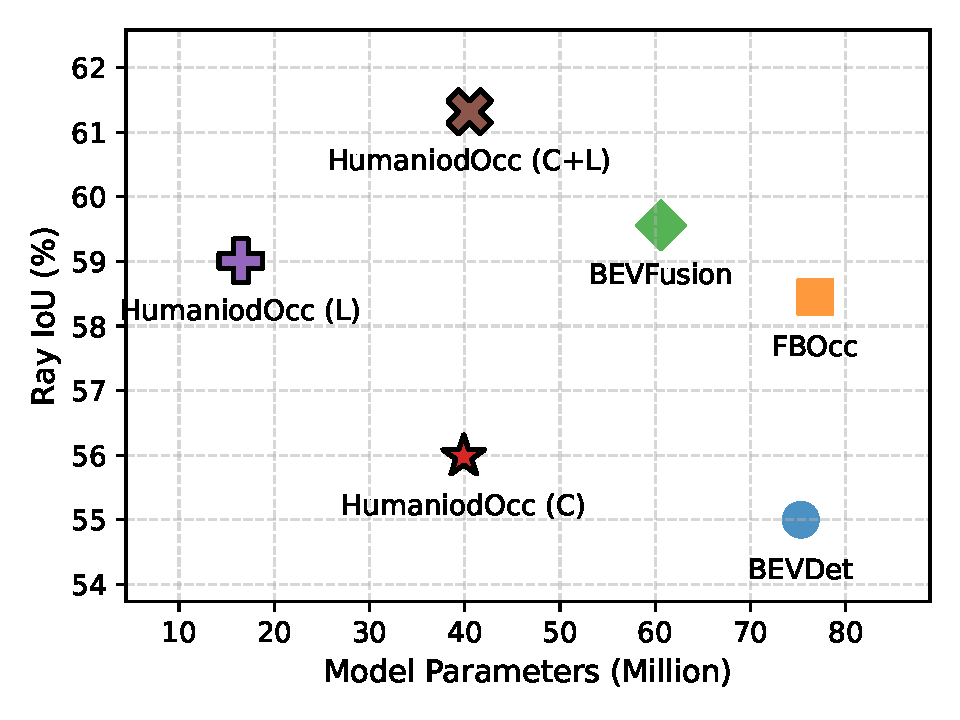
rayIoU Performance
We benchmark our method against representative BEV perception models on our multi-modal dataset. All models adopt identical training configurations. Our model achieves superior metrics while maintaining lightweight architecture with significantly fewer parameters.
Visualization Result
For more details on data analysis and experiment results, please refer to our paper.
BibTeX
@misc{cui2025humanoidoccupancyenablinggeneralized,
title={Humanoid Occupancy: Enabling A Generalized Multimodal Occupancy Perception System on Humanoid Robots},
author={Wei Cui and Haoyu Wang and Wenkang Qin and Yijie Guo and Gang Han and Wen Zhao and Jiahang Cao and Zhang Zhang and Jiaru Zhong and Jingkai Sun and Pihai Sun and Shuai Shi and Botuo Jiang and Jiahao Ma and Jiaxu Wang and Hao Cheng and Zhichao Liu and Yang Wang and Zheng Zhu and Guan Huang and Jian Tang and Qiang Zhang},
year={2025},
eprint={2507.20217},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2507.20217}}